Text analytics and natural language processing (NLP) are often portrayed as ultra-complex computer science functions that can only be understood by trained data scientists. But the core concepts are pretty easy to understand even if the actual technology is quite complicated. In this article I’ll review the basic functions of text analytics and explore how each contributes to deeper natural language processing features.
Quick background: text analytics (also known as text mining) refers to a discipline of computer science that combines machine learning and natural language processing (NLP) to draw meaning from unstructured text documents. Text mining is how a business analyst turns 50,000 hotel guest reviews into specific recommendations; how a workforce analyst improves productivity and reduces employee turnover; how healthcare providers and biopharma researchers understand patient experiences; and much, much more.
Okay, now let’s get down and dirty with how text analytics really works.
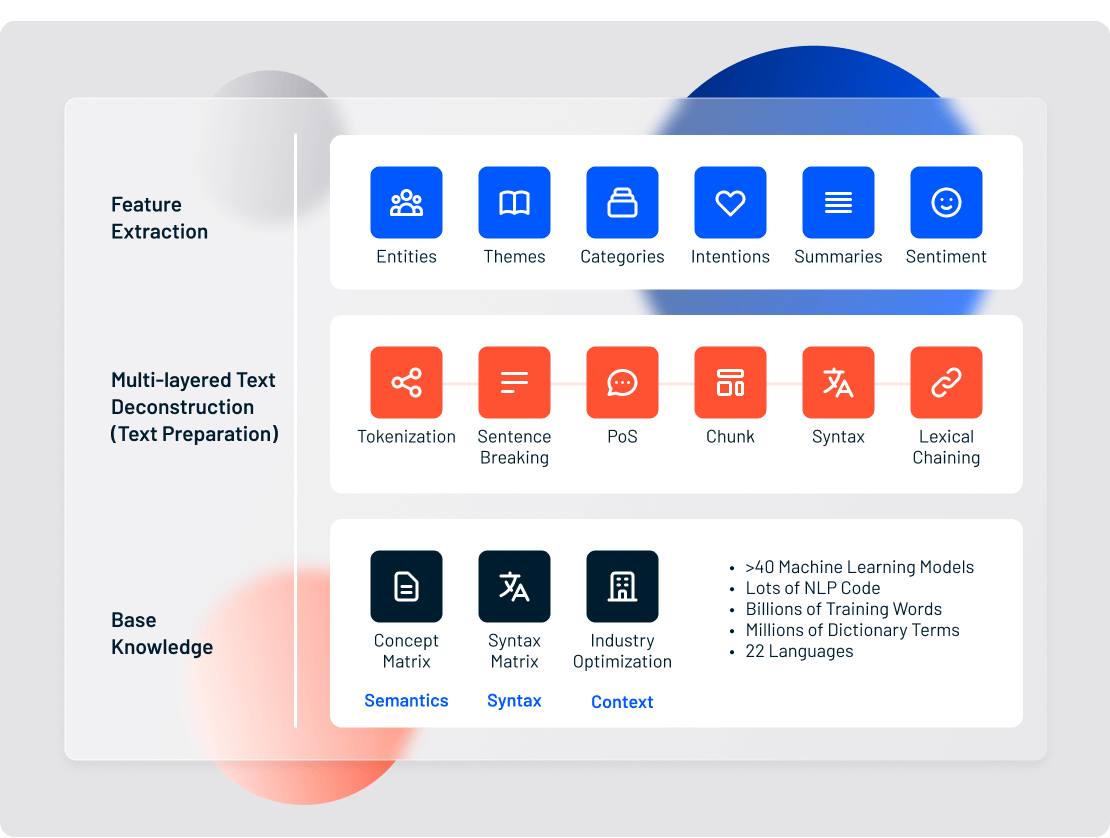
The 7 Basic Functions of Text Analytics
Much like a student writing an essay on Hamlet, a text analytics engine must break down sentences and phrases before it can actually analyze anything. Tearing apart unstructured text documents into their component parts is the first step in pretty much every NLP feature, including named entity recognition, theme extraction, and sentiment analysis.
There are 7 basic steps involved in preparing an unstructured text document for deeper analysis:
- Language Identification
- Tokenization
- Sentence Breaking
- Part of Speech Tagging
- Chunking
- Syntax Parsing
- Sentence Chaining
Each step is achieved on a spectrum between pure machine learning and pure software rules. Let’s review each step in order, and discuss the contributions of machine learning and rules-based NLP.
1. Language Identification
The first step in text analytics is identifying what language the text is written in. Spanish? Singlish? Arabic? Each language has its own idiosyncrasies, so it’s important to know what we’re dealing with.
As basic as it might seem, language identification determines the whole process for every other text analytics function. So it’s very important to get this sub-function right.
Lexalytics supports 29 languages (first and final shameless plug) spanning dozens of alphabets, abjads and logographies.
2. Tokenization
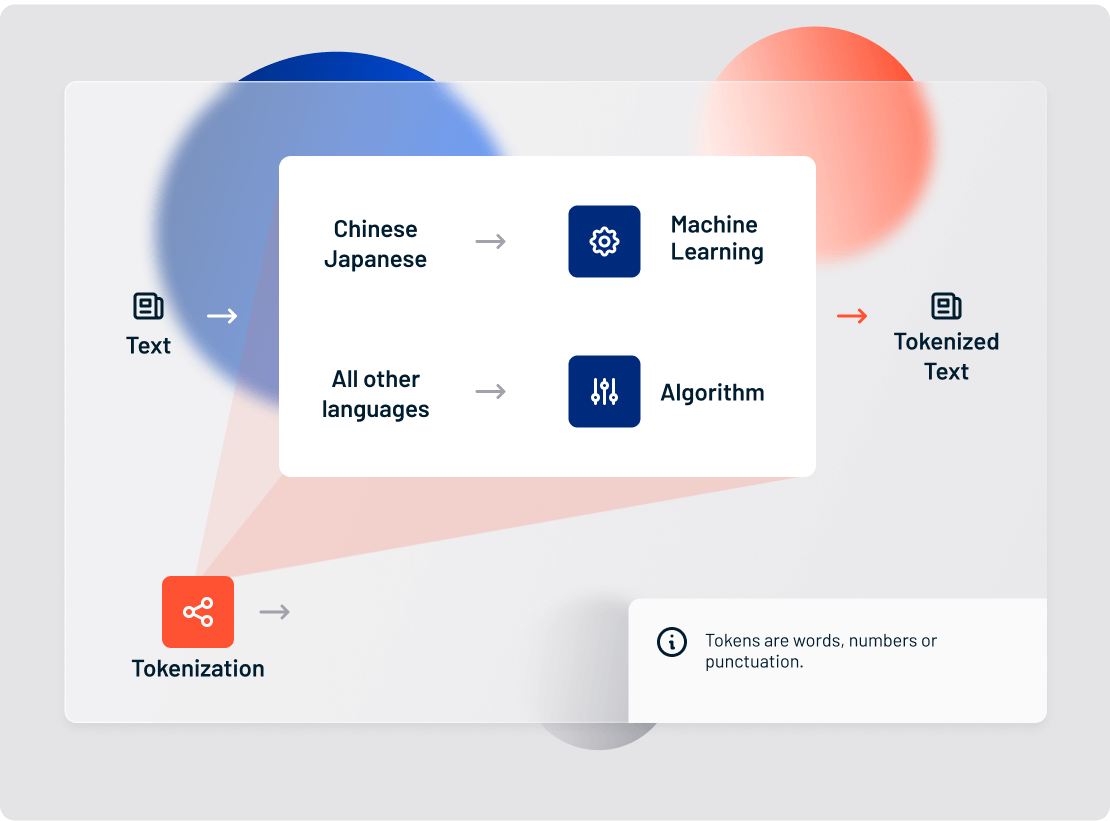
Now that we know what language the text is in, we can break it up into pieces. Tokens are the individual units of meaning you’re operating on. This can be words, phonemes, or even full sentences. Tokenization is the process of breaking text documents apart into those pieces.
In text analytics, tokens are most frequently just words. A sentence of 10 words, then, would contain 10 tokens. For deeper analytics, however, it’s often useful to expand your definition of a token. For Lexalytics, tokens can be:
- Words
- Punctuation (exclamation points intensify sentiment)
- Hyperlinks (https://…)
- Possessive markers (apostrophes)
Tokenization is language-specific, and each language has its own tokenization requirements. English, for example, uses white space and punctuation to denote tokens, and is relatively simple to tokenize.
In fact, most alphabetic languages follow relatively straightforward conventions to break up words, phrases and sentences. So, for most alphabetic languages, we can rely on rules-based tokenization.
But not every language uses an alphabet.
Many logographic (character-based) languages, such as Chinese, have no space breaks between words. Tokenizing these languages requires the use of machine learning, and is beyond the scope of this article.
3. Sentence Breaking

Once you’ve identified the tokens, you can tell where the sentences end. (See, look at that period right there, you knew exactly where the sentence ended, didn’t you Dr. Smart?)
But look again at the second sentence above. Did it end with the period at the end of “Dr.?”
Now check out the punctuation in that last sentence. There’s a period and a question mark right at the end of it!
Point is, before you can run deeper text analytics functions (such as syntax parsing, #6 below), you must be able to tell where the boundaries are in a sentence. Sometimes it’s a simple process, and other times… not so much.
Certain communication channels <cough> Twitter <cough> are particularly complicated to break down. We have ways of sentence breaking for social media, but we’ll leave that aside for now.
4. Part of Speech Tagging
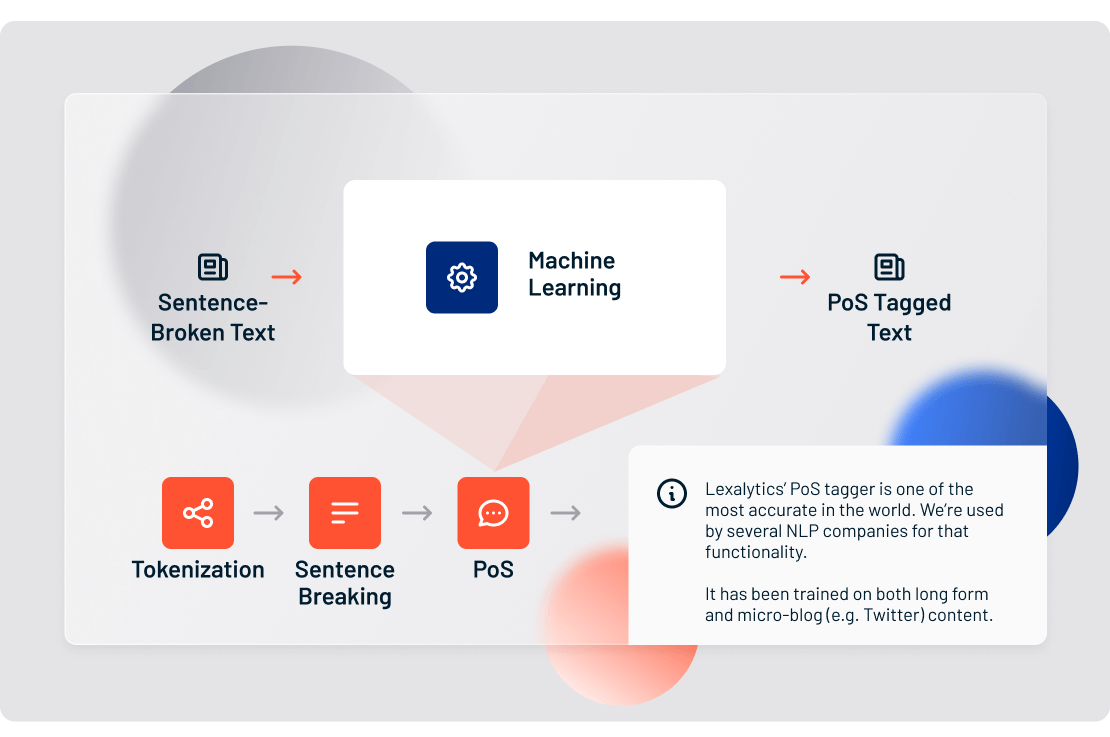
Once we’ve identified the language of a text document, tokenized it, and broken down the sentences, it’s time to tag it.
Part of Speech tagging (or PoS tagging) is the process of determining the part of speech of every token in a document, and then tagging it as such.
For example, we use PoS tagging to figure out whether a given token represents a proper noun or a common noun, or if it’s a verb, an adjective, or something else entirely.
Part of Speech tagging may sound simple, but much like an onion, you’d be surprised at the layers involved – and they just might make you cry. At Lexalytics, due to our breadth of language coverage, we’ve had to train our systems to understand 93 unique Part of Speech tags.
5. Chunking
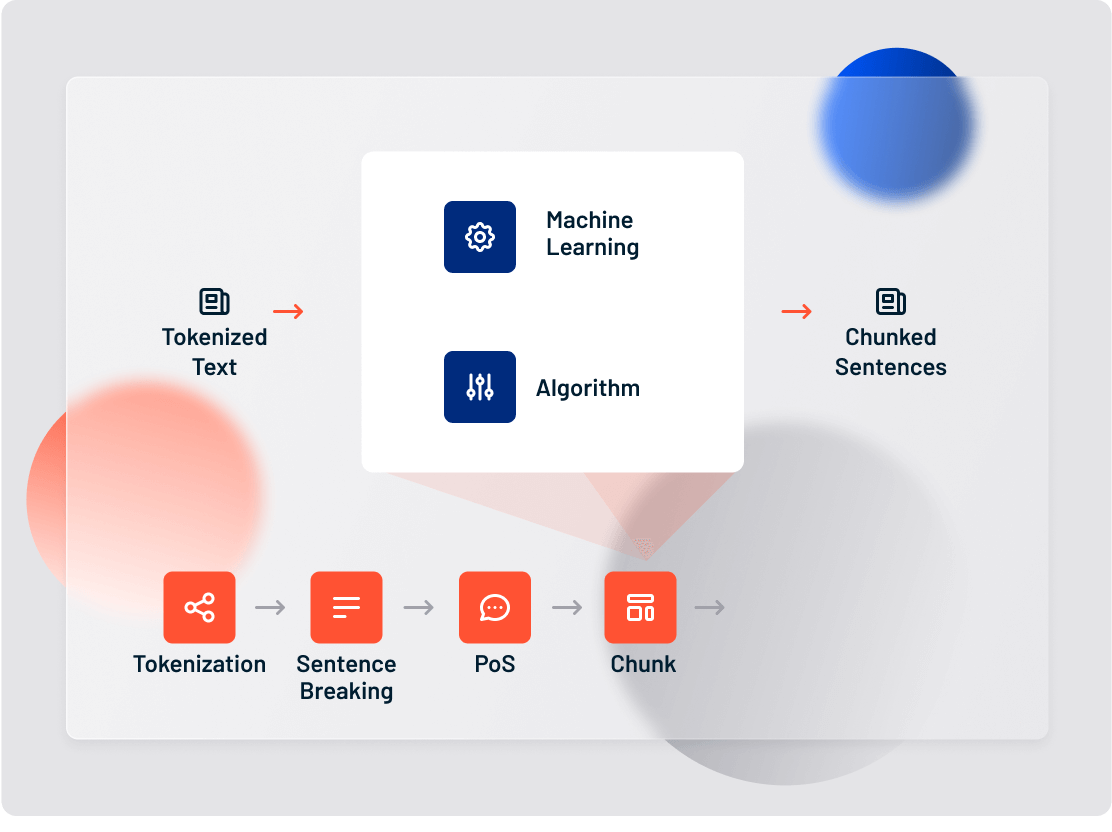
Let’s move on to the text analytics function known as Chunking (a few people call it light parsing, but we don’t). Chunking refers to a range of sentence-breaking systems that splinter a sentence into its component phrases (noun phrases, verb phrases, and so on).
Before we move forward, I want to draw a quick distinction between Chunking and Part of Speech tagging in text analytics.
- PoS tagging means assigning parts of speech to tokens
- Chunking means assigning PoS-tagged tokens to phrases
Here’s what it looks like in practice. Take the sentence:
The tall man is going to quickly walk under the ladder.
PoS tagging will identify man and ladder as nouns and walk as a verb.
Chunking will return: [the tall man]_np [is going to quickly walk]_vp [under the ladder]_pp
(np stands for “noun phrase,” vp stands for “verb phrase,” and pp stands for “prepositional phrase.”)
Got that? Let’s move on.
6. Syntax Parsing
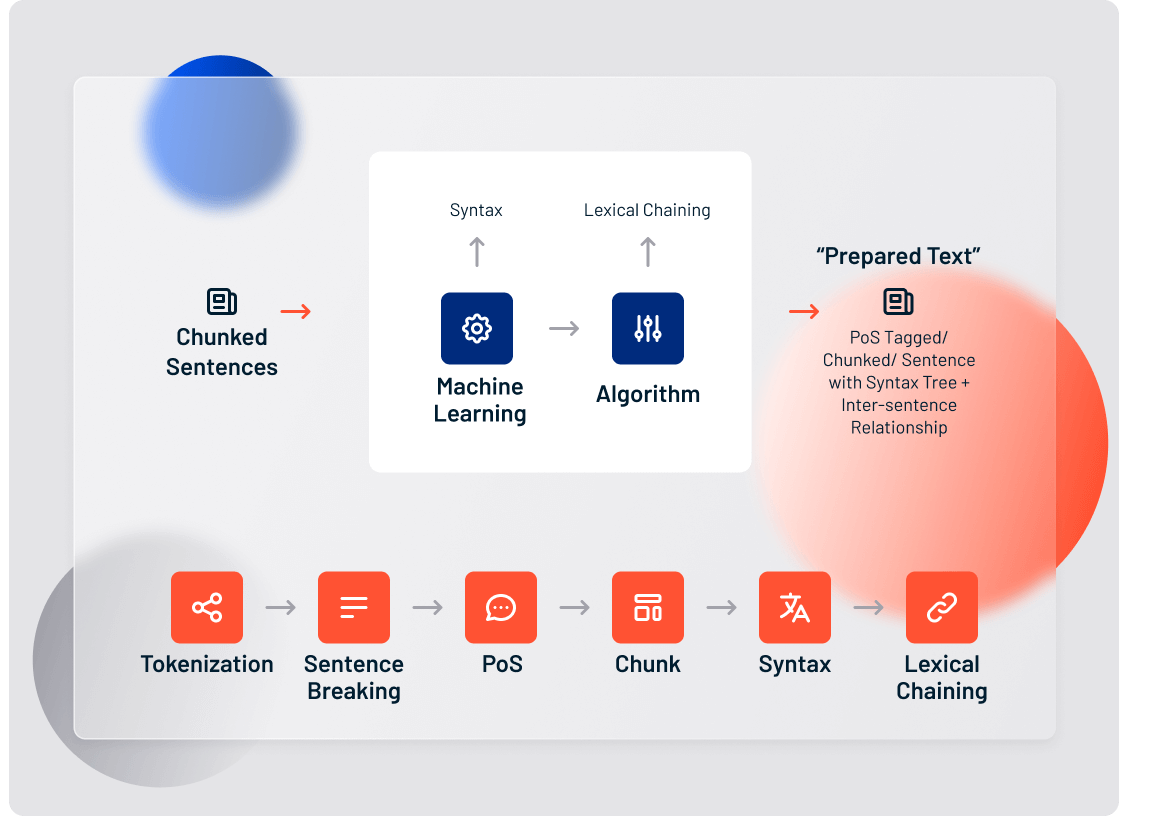
The syntax parsing sub-function is a way to determine the structure of a sentence. In truth, syntax parsing is really just fancy talk for sentence diagramming. But it’s a critical preparatory step in sentiment analysis and other natural language processing features.
This becomes clear in the following example:
- Apple was doing poorly until Steve Jobs…
- Because Apple was doing poorly, Steve Jobs…
- Apple was doing poorly because Steve Jobs…
In the first sentence, Apple is negative, whereas Steve Jobs is positive.
In the second, Apple is still negative, but Steve Jobs is now neutral.
In the final example, both Apple and Steve Jobs are negative.
Syntax parsing is one of the most computationally-intensive steps in text analytics. At Lexalytics, we use special unsupervised machine learning models, based on billions of input words and complex matrix factorization, to help us understand syntax just like a human would.
7. Sentence Chaining
The final step in preparing unstructured text for deeper analysis is sentence chaining, sometimes known as sentence relation.
Lexalytics utilizes a technique called “lexical chaining” to connect related sentences. Lexical chaining links individual sentences by each sentence’s strength of association to an overall topic.
Even if sentences appear many paragraphs apart in a document, the lexical chain will flow through the document and help a machine detect overarching topics and quantify the overall “feel.”
In fact, once you’ve drawn associations between sentences, you can run complex analyses, such as comparing and contrasting sentiment scores and quickly generating accurate summaries of long documents.
Further reading and resources
Hungry for more information about text analytics?
I’m a big fan of the Wikipedia article on this subject (don’t tell my high school English teacher). Note that Wikipedia considers Text Analytics and Text Mining to be one and the same thing. I don’t necessarily agree with that position, but we’ll discuss that another time.
You can also visit to our technology pages for more explanations of sentiment analysis, named entity recognition, summarization, intention extraction and more.
Lastly, if you’d like to see text analytics in action, feel free to play around with our free online web demo.