tECH
Document Categorization & Text Classification
Boolean queries, machine learning classifiers, auto-categories and concept topics
What is document categorization (text classification)?
Categorization in text mining means sorting documents into groups. Automatic document classification uses a combination of natural language processing (NLP) and machine learning to categorize customer reviews, support tickets, or any other type of text document based on their contents.
Note: In this context, we use the terms document categorization and document classification synonymously.
NLP-based document categorization enables you to sort through huge numbers of documents without actually reading them yourself. Much like a librarian places a book about horses on a shelf labeled “Animals,” an NLP classifier can categorize a product description as “Sauces” because the text mentions ketchup or mustard. And because text classifiers work at the speed of computers, they can categorize thousands of documents in less time than it takes to drink your morning coffee. Rather than painstakingly sorting through them by hand, you can immediately find and focus on the documents you care about.
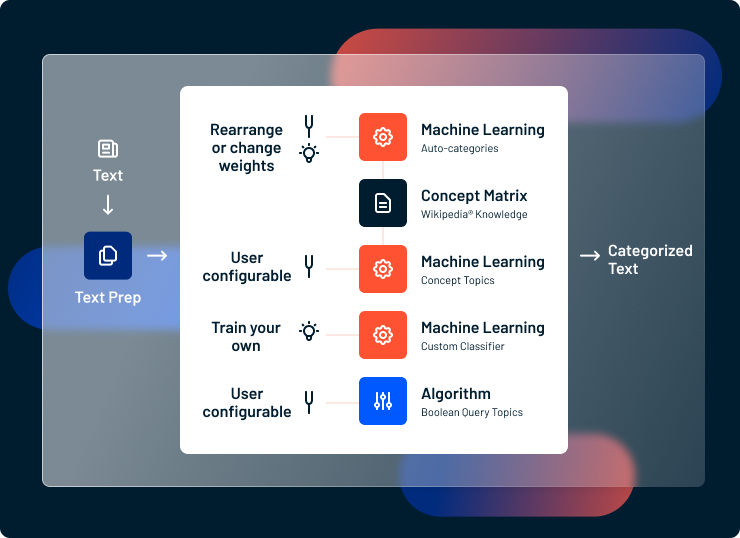
Lexalytics multiple methods of categorization
Four Methods of Document Categorization
Lexalytics supports four methods of document categorization.
Query Topics use Boolean operators to decide whether a document belongs in a given category by looking for the presence or absence of key words and phrases. Queries are simple to understand, easy to set up, and work best when you know that a particular set of words are useful as categorization markers. But the more meanings a word has, the more layers you need to add to your query topic. This can become cumbersome, unreliable and unsustainable.
Boolean Operators
- AND
- OR
- NOT
- WITH
- NEAR
- CONTEXT
Machine learning models categorize documents by identifying statistical connections between words and phrases and human-provided examples of where documents should be sorted. In effect, text classification algorithms, including Support Vector Machines (SVM) and Naive Bayes, learn the likelihood that a given set of words are related to a particular category. Model-based classifiers are efficient and require less human input than queries. But models require a training set of data to learn from, and, without maintenance, will quickly grow obsolete.
Auto-Categories use the Lexalytics Concept Matrix™ to compare your documents to 400 first-level categories and 4,000 second-level categories based on Wikipedia’s own taxonomy. Auto-categories work out of the box, requiring no customization at all. They’re the easiest tool to use in our categorization toolbox but cannot be changed or tuned.
Sample Auto-Categories
- Business, Interest
- Computers, Computer_keyboards
- Condiments_and_Sweeteners, Marinades
- Energy, Fuel_gas
- Fashion, Jackets
- Food, Savoury_pies
Concept Topics use the Concept Matrix to broaden the scope of a user-defined category beyond a few example keywords. When you create a new Concept Topic, you’re asked to give 4-6 examples of words that fall into that category. Then we use the Concept Matrix to find other words that are semantically related to the larger idea.
Auto-Categories and Concept Topics are good at sorting content into broader, idea-based categories but don’t work as well on shorter documents.
A Hybrid Approach to Document Categorization
Most text categorization tools rely on only one or two of the methods outlined above. Because Lexalytics supports all four, we’re able to solve a wider range of document classification use cases. And where others limit your ability to customize your queries, category taxonomies and models, we give you access to configure everything to meet your exact needs.
We also run sentiment analysis on each category to show you the positive or negative opinions expressed within the documents that fall into that category. From there, you can drill down to discover why people feel that way.
To learn more about Lexalytics’ hybrid approach to text document categorization, read our white paper: Categorization and Classification of Text Documents.
Applications of Document Classification
In simplest terms, applications of NLP-based document classification center around sorting and organizing. Enterprises large and small face a veritable flood of data; automated document categorization helps you manage and profit from it.
To categorize cellphone reviews, for example, business analysts use Boolean queries to group them based on the products mentioned. While medical affairs liaisons at pharmaceutical firms categorize social media comments and news articles to look for mentions of their company’s drugs and therapies.
Tracking Brands & Products:
Microsoft’s Customer Market Research team uses NLP document classification to track more than 1,000 brands and products across the web. Microsoft case study
Support Ticket Classification:
Large enterprises use NLP categorization to sort incoming support tickets and then route them to the appropriate department. Read more
Understanding Opinions:
Barry Nash & Company use categories and other NLP features to identify ideal on-air personality and performance characteristics.
Categorizing Social Media Comments:
Architects at Gensler’s Los Angeles Aviation and Transportation Studio use categories to hear what travelers actually experience. Gensler case study
For more document categorization use cases in social media listening, regulatory compliance, robotic process automation, voice of customer and workforce analytics, visit our Applications page.