Transform Complex Text Documents into Data, Insights, & Value
Integrate our text analytics APIs to add world-leading NLP into your product, platform, or application.
The World's Best Brands Partner With Lexalytics
fully featured
Natural Language Processing
The most feature-complete NLP feature stack on the market, 19 years in development and constantly being improved with new libraries, configurations, and models.
Sentiment Analysis
Determine whether a piece of writing is positive, negative, or neutral.
Categorization
Sort and organize documents into customizable groups.
Entity Extraction
Find people, places, dates, companies, products, jobs, titles, and more.
Intention Detection
Determine the expressed intent of customers and reviewers.
Flexible Deployment
Deploy our text analytics and NLP systems across any combination of on-premise, private cloud, hybrid cloud, and public cloud infrastructure.
Contact us
Salience
Our core text analytics and natural language processing software libraries at your command. Suitable for data scientists and architects who want complete access to the underlying technology or who need on-premise deployment for security or privacy reasons.
Semantria
The capabilities of Salience wrapped into a RESTful API with graphical configuration and user management tools. Integrate into your cloud-based enterprise data analytics infrastructure or deliver powerful text analytics to your own customers.
Spotlight
Store, manage, and analyze unstructured text documents in a complete solution built on the power of the Semantria API. Visualize the results in interactive dashboards and share your findings.
Native Languages
Fully transparent text analytics technology with truly native language support in 29 languages representing 67% of the world’s population spread across 6 continents.
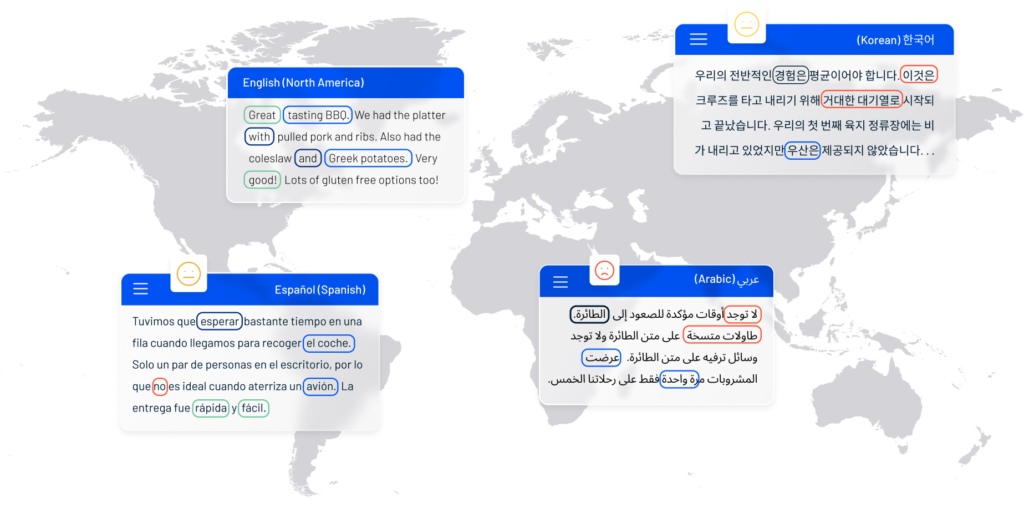
Industry Packs
Pre-built industry configurations for out-of-the-box improvements in sentiment accuracy, topic detection, categorization, and more.
Hotels
Monitor consumer feedback and intentions in areas such as rooms, staff, service, and food
Restaurants
Whether a chain or fine dining, stay on top of diner sentiment towards food and service
Retail
Hear what's going on as customers interact with staff, products, and locations throughout their shopping experience.
Pharma
Medications, symptoms, conditions, diseases, dosages, anatomical terms, specialties, plus 250 ICD-10 codes mapped to normalized names
Voice of Employee
How do employees think about management, benefits, opportunities, work-life balance, and more
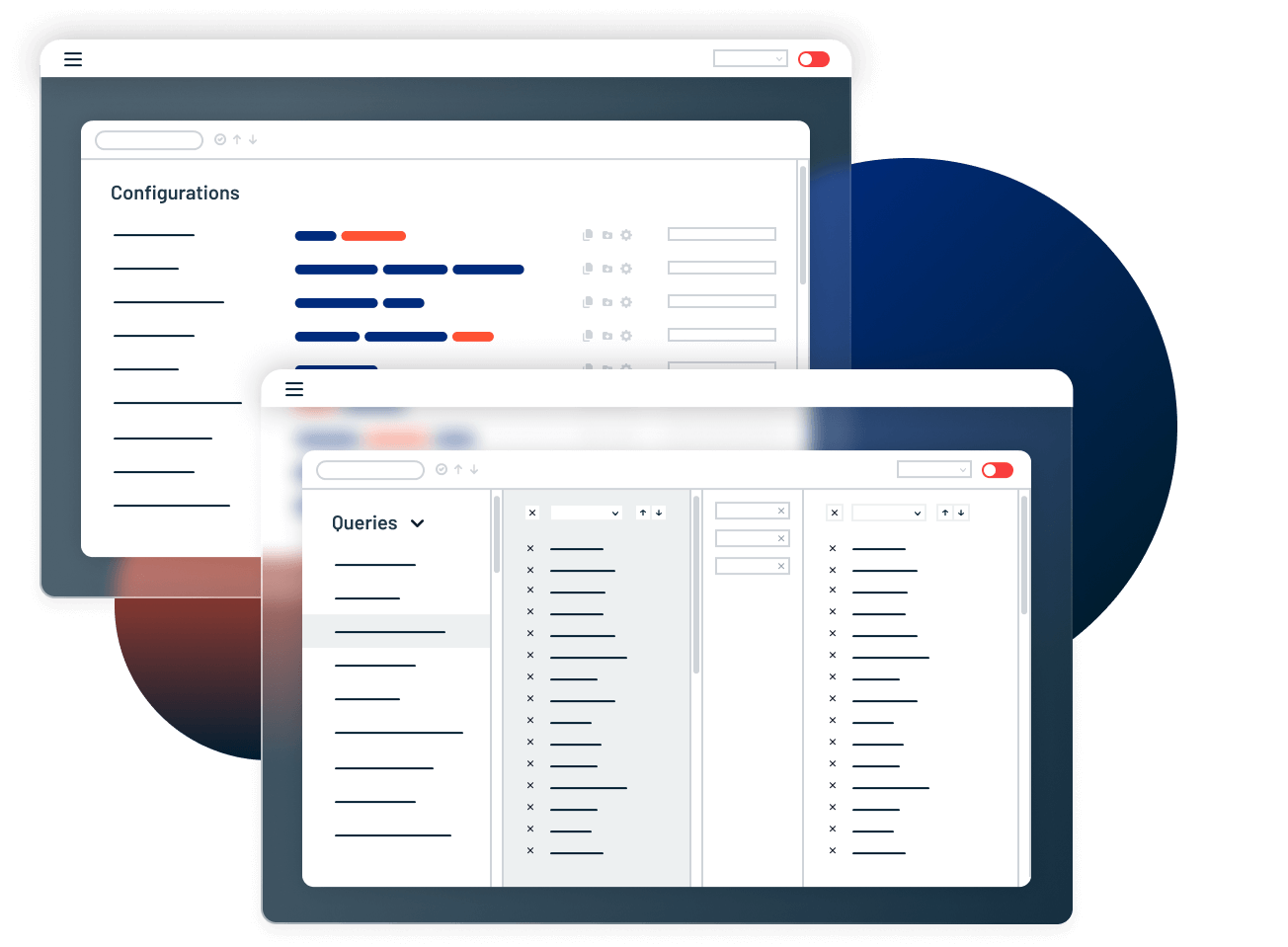
Easy Configuration & Tuning
When you need to go beyond our out-of-the-box results, access the control you need. Define custom entities, create new query topics, build category taxonomies, add blacklists, and more through our intuitive configuration tools.
Deploy Custom Machine Learning Models
Hundreds of machine learning models already deployed to improve our core text analytics, and custom-trained machine learning “micromodels” to tackle unique challenges in your data when needed.
Popular Pieces
Take a look at our case studies, data sheets and whitepapers.

Lexalytics, an InMoment Company, Recognized for Artificial Intelligence Innovation in 2023 AI Breakthrough Awards for Best Overall NLP Company
Read press…
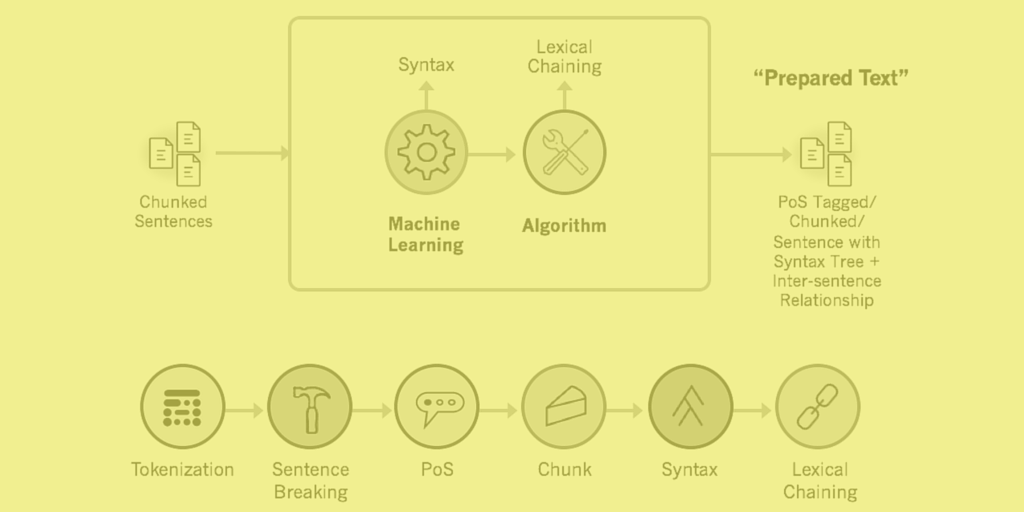
Natural Language Processing
The 7 Basic Functions of Text Analytics & Text Mining
From Tokenization to PoS Tagging and beyond, this high-level overview explains the basic functions of text analytics…
Technology
Build vs Buy: Text Analytics & NLP
From customization to scalability, there’s a lot to consider when deciding whether to build or buy an NLP or system. In…