TECH
Text Analytics
What is Text Analytics?
Text analytics is the process of transforming unstructured text documents into usable, structured data. Text analysis works by breaking apart sentences and phrases into their components, and then evaluating each part’s role and meaning using complex software rules and machine learning algorithms.
Text analytics forms the foundation of numerous natural language processing (NLP) features, including named entity recognition, categorization, and sentiment analysis. In broad terms, these NLP features aim to answer four questions:
- Who is talking?
- What are they talking about?
- What are they saying about those subjects?
- How do they feel?
Data analysts and other professionals use text mining tools to derive useful information and context-rich insights from large volumes of raw text, such as social media comments, online reviews, and news articles. In this way, text analytics software forms the backbone of business intelligence programs, including voice of customer/customer experience management, social listening and media monitoring, and voice of employee/workforce analytics.
This article will cover the basics of text analytics, starting with the difference between text analytics, text mining, and natural language processing. Then we’ll explain the seven functions of text analytics and explore some basic applications of text mining. Finally, we’ll tell you where you can try text analytics for free and share some resources for further reading.
Table of contents:
- Defining terms
- How text analytics works
- Basic applications
- Further reading
What is the difference between text mining, text analytics and natural language processing?
Text mining
describes the general act of gathering useful information from text documents.
Text analytics
refers to the actual computational processes of breaking down unstructured text documents, such as tweets, articles, reviews and comments, so they can be analyzed further.
Natural language processing (NLP)
is how a computer understands the underlying meaning of those text documents: who’s talking, what they’re talking about, and how they feel about those subjects.
As a term, text mining is often used interchangeably with text analytics. In most cases, that’s fine. But there is a difference. If text mining refers to collecting useful information from text documents, text analytics is how a computer actually transforms those raw words into information. Meanwhile, the low-level computational functions of text analytics form the foundation of natural language processing features, such as sentiment analysis, named entity recognition, categorization, and theme analysis.
How does text analytics work?
Text analytics starts by breaking down each sentence and phrase into its basic parts. Each of these components, including parts of speech, tokens, and chunks, serve a vital role in accomplishing deeper natural language processing and contextual analysis.
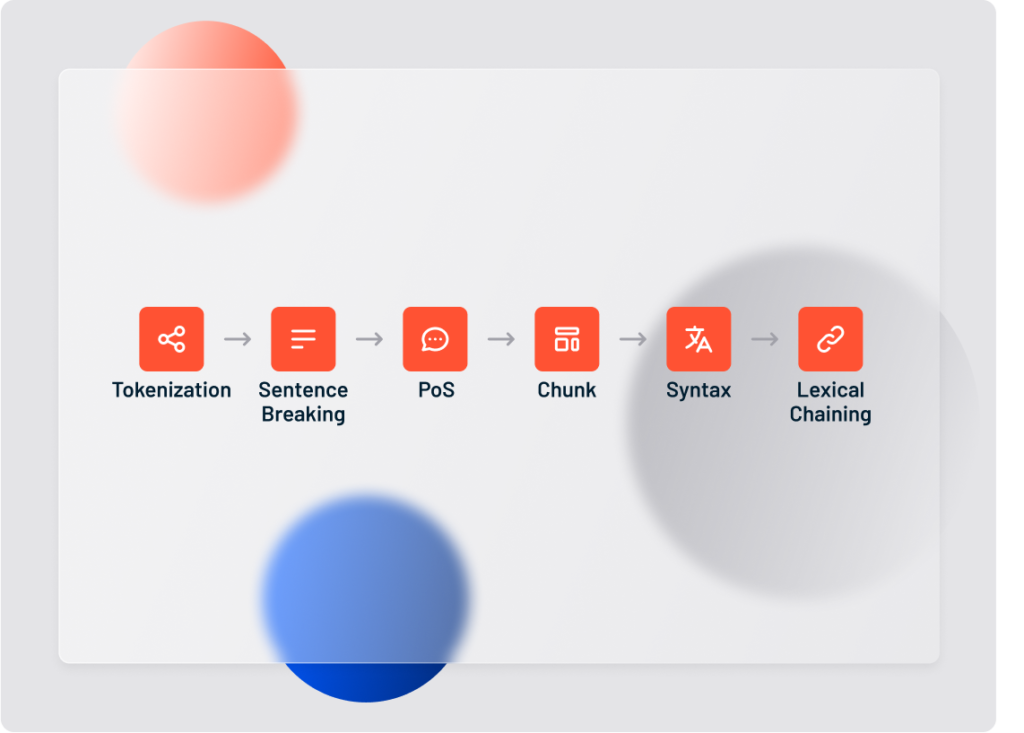
There are seven computational steps involved in preparing an unstructured text document for deeper analysis:
- Language Identification
- Tokenization
- Sentence breaking
- Part of Speech tagging
- Chunking
- Syntax parsing
- Sentence chaining
Some text analytics functions are accomplished exclusively through rules-based software systems. Other functions require machine learning models (including deep learning algorithms) to achieve.

1. Language identification
The first step in text analytics is identifying what language the text is written in. Spanish? Russian? Arabic? Chinese?
Lexalytics supports text analytics for more than 30 languages and dialects. Together, these languages include a complex tangle of alphabets, abjads and logographies. Each language has its own idiosyncrasies and unique rules of grammar. So, as basic as it might seem, language identification determines the whole process for every other text analytics function.
2. Tokenization
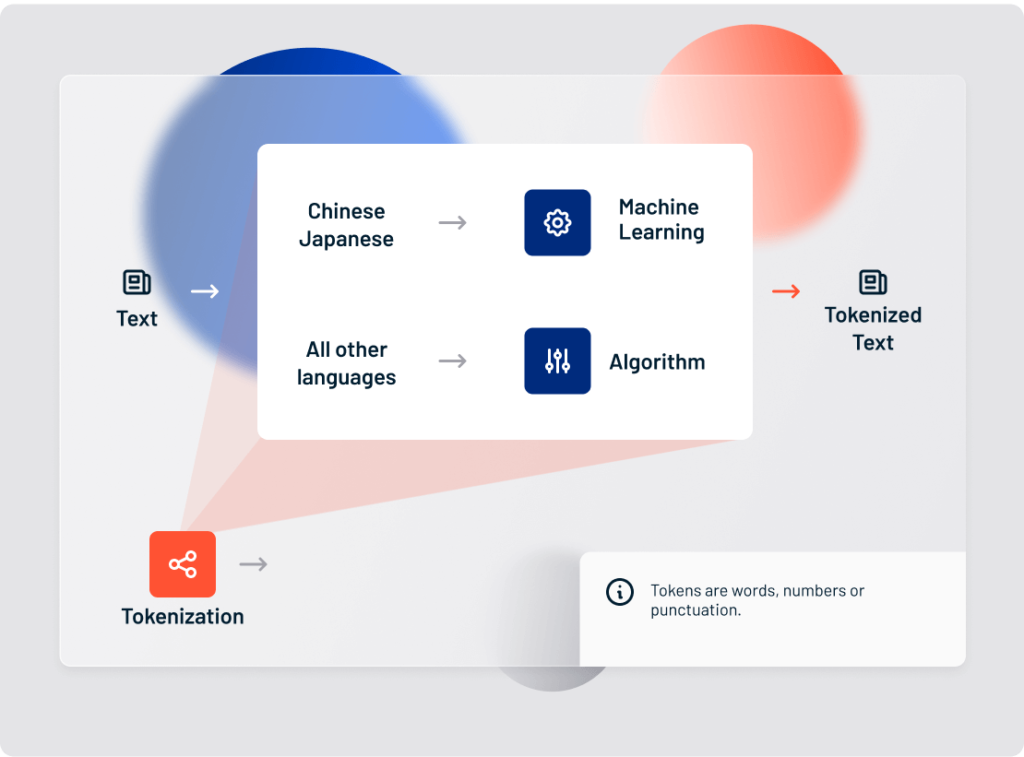
Tokenization is the process of breaking apart a sentence or phrase into its component pieces. Tokens are usually words or numbers. Depending on the type of unstructured text you’re processing, however, tokens can also be:
- Punctuation (exclamation points amplify sentiment)
- Hyperlinks (https://…)
- Possessive markers (apostrophes)
Tokenization is language-specific, so it’s important to know which language you’re analyzing. Most alphabetic languages use whitespace and punctuation to denote tokens within a phrase or sentence. Logographic (character-based) languages such as Chinese, however, use other systems.
Lexalytics uses rules-based algorithms to tokenize alphabetic languages, but logographic languages require the use of complex machine learning algorithms.
3. Sentence breaking
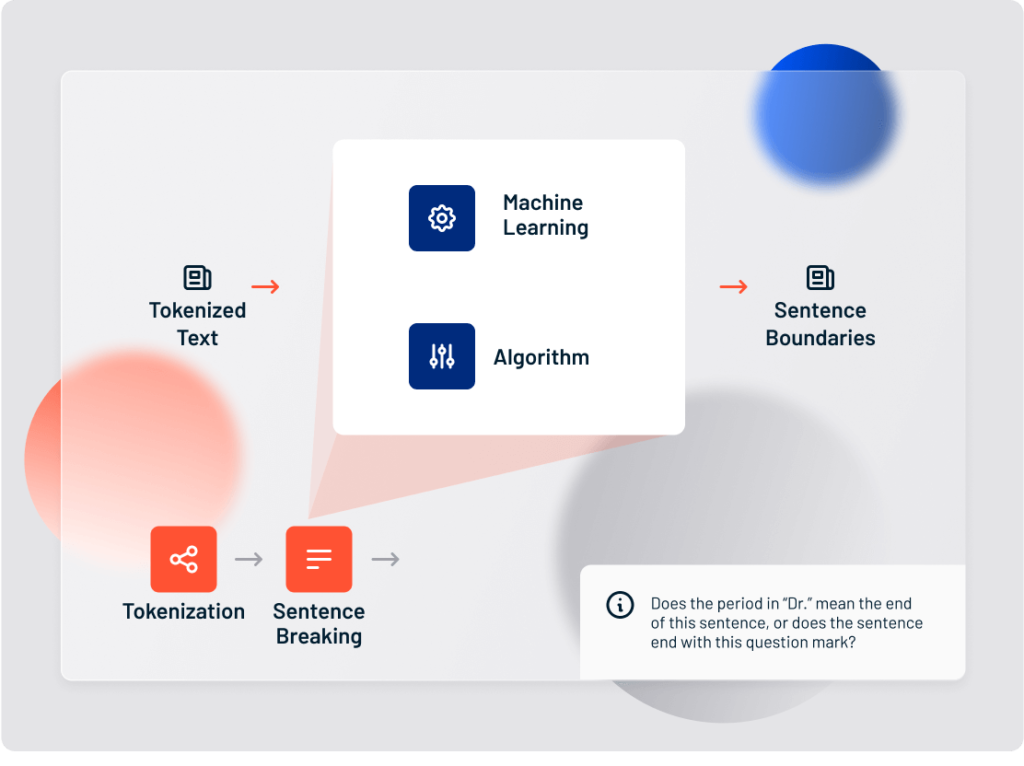
Small text documents, such as tweets, usually contain a single sentence. But longer documents require sentence breaking to separate each unique statement. In some documents, each sentence is separated by a punctuation mark. But some sentences contain punctuation marks that don’t mean the end of the statement (like the period in “Dr.”)
4. Part of Speech tagging
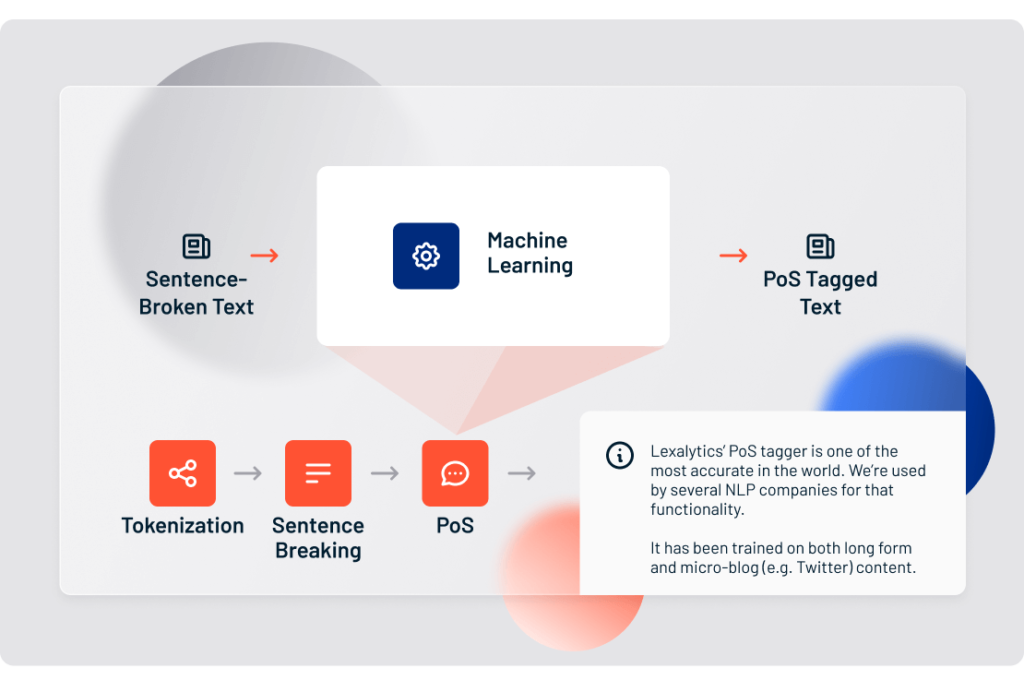
Part of Speech tagging (or PoS tagging) is the process of determining the part of speech of every token in a document, and then tagging it as such. Most languages follow some basic rules and patterns that can be written into a basic Part of Speech tagger. When shown a text document, the tagger figures out whether a given token represents a proper noun or a common noun, or if it’s a verb, an adjective, or something else entirely.
Accurate part of speech tagging is critical for reliable sentiment analysis. Through identifying adjective-noun combinations, a sentiment analysis system gains its first clue that it’s looking at a sentiment-bearing phrase. At Lexalytics, due to our breadth of language coverage, we’ve had to train our systems to understand 93 unique Part of Speech tags.
5. Chunking
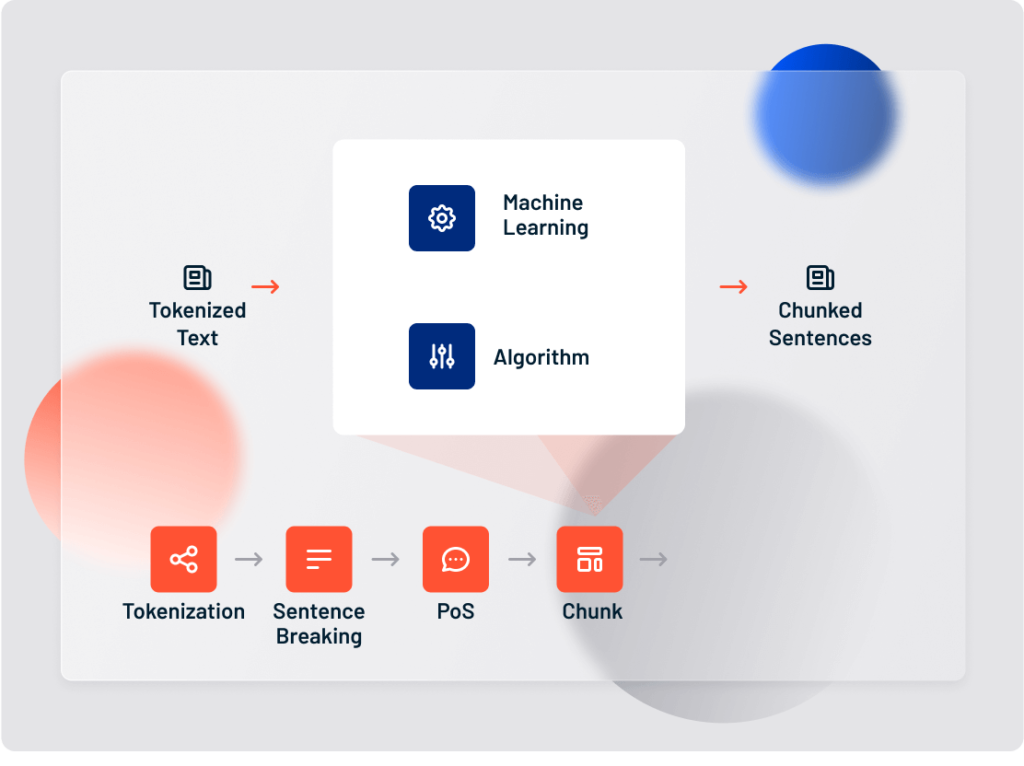
Chunking refers to a range of sentence-breaking systems that splinter a sentence into its component phrases (noun phrases, verb phrases, and so on).
Chunking in text analytics is different than Part of Speech tagging:
- PoS tagging means assigning parts of speech to tokens
- Chunking means assigning PoS-tagged tokens to phrases
For example, take the sentence:The tall man is going to quickly walk under the ladder.
PoS tagging will identify man and ladder as nouns and walk as a verb.
Chunking will return: [the tall man]_np [is going to quickly walk]_vp [under the ladder]_pp
(np stands for “noun phrase,” vp stands for “verb phrase,” and pp stands for “prepositional phrase.”)
6. Syntax parsing
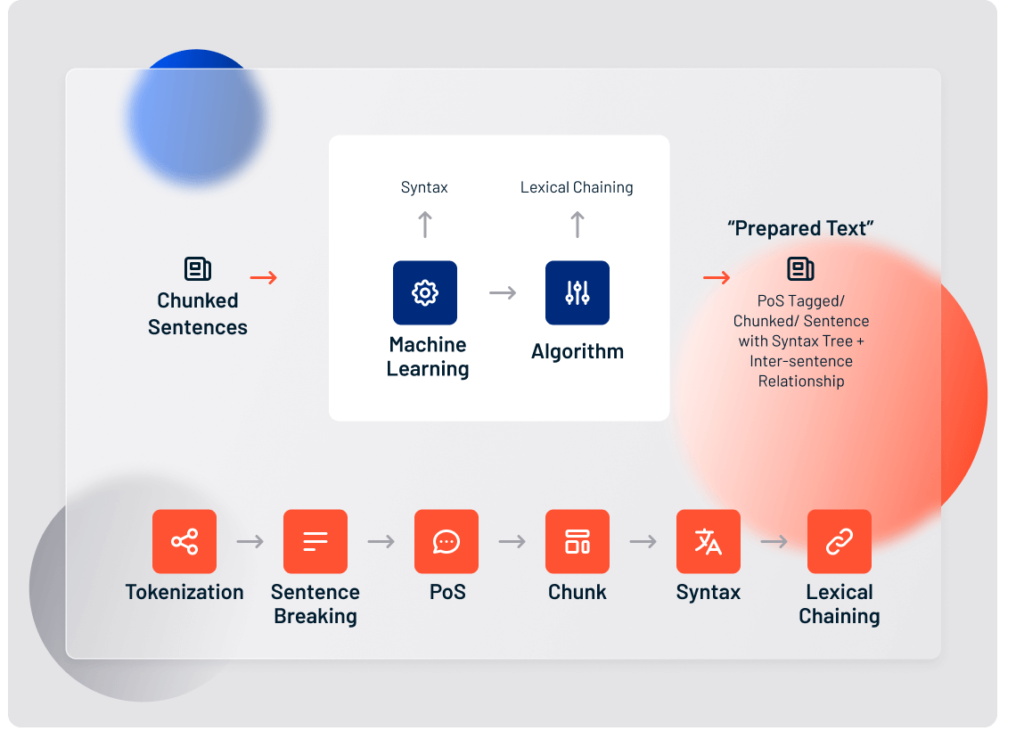
Syntax parsing is the analysis of how a sentence is formed. Syntax parsing is a critical preparatory step in sentiment analysis and other natural language processing features.
The same sentence can have multiple meanings depending on how it’s structured:
- Apple was doing poorly until Steve Jobs…
- Because Apple was doing poorly, Steve Jobs…
- Apple was doing poorly because Steve Jobs…
In the first sentence, Apple is negative, whereas Steve Jobs is positive.
In the second, Apple is still negative, but Steve Jobs is now neutral.
In the final example, both Apple and Steve Jobs are negative.
Syntax parsing is one of the most computationally-intensive steps in text analytics. At Lexalytics, we use special unsupervised machine learning models, based on billions of input words and complex matrix factorization, to help us understand syntax just like a human would.
7. Sentence chaining
The final step in preparing unstructured text for deeper analysis is sentence chaining. Sentence chaining uses a technique called lexical chaining to connect individual sentences based on their association to a larger topic. Take the sentences:
- I like beer.
- Miller just launched a new pilsner.
- But I only drink Belgian ale.
Even if these sentences don’t appear near each other in a body of text, they are still connected to each other through the topics of beer->pilsner->ale. Lexical chaining allows us to make these kinds of connections. The “score” of a lexical chain is directly related to the length of the chain and the relationships between the chaining nouns (same words, antonyms, synonyms, homonyms, meronyms, hypernyms or holonyms).
Lexical chains flow through the document and help a machine detect over-arching topics and quantify the overall “feel”. Lexalytics uses sentence chaining to weight individual themes, compare sentiment scores and summarize long documents.
Basic applications of text mining and natural language processing
Text mining and natural language processing technologies add powerful historical and predictive analytics capabilities to business intelligence and data analytics platforms. The flexibility and customizability of these systems make them applicable across a wide range of industries, such as hospitality, financial services, pharmaceuticals, and retail.
Broadly speaking, applications of text mining and NLP fall into three categories:
Voice of Customer
Customer Experience Management and Market Research
It can take years to gain a customer, but only minutes to lose them. Business analysts use text mining tools to understand what consumers are saying about their brands, products and services on social media, in open-ended experience surveys, and around the web. Through sentiment analysis, categorization and other natural language processing features, text mining tools form the backbone of data-driven Voice of Customer programs.
Read more about text analytics for Voice of Customer
Social Media Monitoring
Social Listening and Brand Management
Social media users generate a goldmine of natural-language content for brands to mine. But social comments are usually riddled with spelling errors, and laden with abbreviations, acronyms, and emoticons. The sheer volume poses a problem, too. On your own, analyzing all this data would be impossible. Business Intelligence tools like the Lexalytics Intelligence Platform use text analytics and natural language processing to quickly transform these mountains of hashtags, slang, and poor grammar into useful data and insights into how people feel, in their own words.
Read more about text analytics for Social Media Monitoring
Voice of Employee
Workforce Analytics and Employee Satisfaction
The cost of replacing a single employee can range from 20-30% of salary. But companies struggle to attract and retain good talent. Structured employee satisfaction surveys rarely give people the chance to voice their true opinions. And by the time you’ve identified the causes of the factors that reduce productivity and drive employees to leave, it’s too late. Text analytics tools help human resources professionals uncover and act on these issues faster and more effectively, cutting off employee churn at the source.
Read more about text analytics for Voice of Employee
Further reading
Try text analytics and text mining for free
Text analytics and NLP in action:
Try our web demo for a quick sample of Lexalytics’ own text analytics and NLP features
Contact us for a live demo with your data, or to discuss our on-premise and cloud APIs
Build your own text analytics system:
Start working with the Stanford NLP or Natural Language Toolkit (NLTK) open source distributions
Browse this Predictive Analytics list of 27 free text analytics toolkits
Take a Coursera course on Text Mining and Analytics
Learn more about text analytics
Read about sentiment analysis and other natural language processing features
Explore the difference between machine learning and natural language processing
Dive deep with this practitioner’s guide to NLP on KDnuggets