This article explains everything you need to know about text analytics and natural language processing in robotic process automation. First, we define RPA and natural language processing, and explain how they fit together. Then we outline a number of trending text analytics use cases in RPA. Finally, we cite Forrester and Gartner to put these use cases in perspective and explain how the RPA market is changing, and where it’s going. As we demonstrate, the future of RPA is in better analytics and customization with larger, transformational use cases. To stay ahead, RPA vendors must improve their NLP capabilities.
What is Robotic Process Automation (RPA)?
Robotic Process Automation (RPA) refers to automating repetitive, “rules-based” business operations tasks, often involving data processing or routing. RPA reduces costs and increases profitability for enterprises by freeing workers to focus on higher-value work.
Companies use RPA tools to configure automation scripts, often referred to as “robots”. These “bots” fall into two categories: unattended and attended.
Unattended automations execute tasks and interact with other applications without any human input. They are often simple, “straight-through” scripts that move data into or out of third-party systems. For example, if a claims processor records the contents of an insurance form, an unattended automation might take that data and distribute across a number of databases.
Attended automations augment employee capabilities by offloading portions of tasks. This frequently means extracting information from systems and documents and then preparing it to be ready whenever an employee needs it. Attended automations require human input, such as telling it what data to access or which documents to pull it from.
Each RPA bot may work alone to automate a single task, such as categorizing a support ticket. Or a number of robots may coordinate to automate a more complex process, such as extracting data from a scanned invoice, analyzing it to understand the roles and values involved, and then automatically triggering a transaction from accounts payable.
What is Natural Language Processing (NLP) in RPA?
Natural language processing (NLP) is a branch of computer science that deals with teaching computers to understand human language, as humans actually use it. First, low-level text analytics functions break phrases down into their component parts, including tokens and parts of speech. Then NLP models decipher meaning from those pieces, such as analyzing their sentiment, categorizing them into buckets, or recognizing specific named entities.
Natural language processing in RPA analyzes structured, unstructured and “semi-structured” documents to identify, extract and structure data within them for further analysis. NLP applications in RPA fall into two categories: structured and semi-structured document processing, and unstructured document use cases.
The first group of NLP applications for RPA covers structured and semi-structured document use cases. These include invoice processing, insurance claim handling, and contract analysis. NLP for structured and semi-structured document processing helps companies accelerate and automate existing business processes, reducing costs by freeing up workers to focus on higher-value tasks.
Unstructured document use cases in RPA align more closely with traditional Voice of Customer (VoC) and Voice of Employee (VoE) initiatives. Common automations include using NLP for customer review analysis, support ticket classification, and various workforce analytics functions. Using NLP for VoC and VoE process automation helps companies increase revenue by improving customer experiences, improving employee engagement, and guiding product roadmaps.
Solving Two of the Biggest Challenges Facing NLP in RPA
One major challenge of NLP in RPA is in accounting for context. The documents involved in RPA, such as contracts and financial filings, are written in text but have structured sections that add context to the words within. For example, it’s useful to know that a land deed mentions a company, a person and a bank. But it’s even more valuable to know that they refer to a “Lender,” a “Borrower” and a “Trustee”, respectively. To solve these context problems, we combine a semi-structured data parser with NLP machine learning models. These technologies work together to account for how the structure of a document influences the data within it.
Another challenge lies in parsing the vagaries and inconsistencies of natural language. Tweets are full of spelling errors, Google reviews rarely follow the rules of proper grammar, and customer support tickets can be all over the map.![[thoughtful man reading a document, with sentiment emojis for positive, neutral and negative sentiment.png]](https://www.lexalytics.com/wp-content/uploads/2022/04/190404-266x300.png) What’s more, every language has its own rules and idiosyncrasies to account for.
What’s more, every language has its own rules and idiosyncrasies to account for.
For a simple example, consider a tweet that says, “That chicken parmesan was stupidly good.” You and I instinctively know that even though “stupid” usually means something bad, in this context the adverb “stupidly” actually intensifies the sentiment weight of “good”. But in a different context, “stupidly” would carry negative sentiment.
NLP systems combine software rules and machine learning mode to understand nuance like this. To learn more, visit our technology pages on text analytics and sentiment analysis.
Text Analytics and Natural Language Processing Use Cases in Robotic Process Automation
NLP use cases in RPA can be divided into two categories. One group focuses on processing structured and semi-structured documents that contain contain mixed elements and inconsistent data: invoices, mortgage applications, insurance claims, regulatory updates, medical files, financial filings, contracts, and so on. The other group, unstructured document use cases, handles more free-form content. These applications align well with traditional Voice of Customer, Customer Experience, Voice of Employee and Workforce Analytics programs.
Support Ticket Classification for Faster Triage and Deeper Customer Experience Analytics
Large enterprises are faced with hundreds, even thousands, of new support tickets every day. These might be customer requests through Zendesk or Desk.com, employee tickets through ServiceNow, email sent to a support@company.com address, or even social media posts with a support tag. Each one needs to be sorted and then routed to the appropriate department, team, or individual for resolution. Later, business analysts use these categories to uncover trends and patterns over time.
Some companies do this manually. A tech company might assign someone to review, tag, and route customer tickets as they come in. In other businesses, call centers in particular, agents have to hand-tag each customer interaction at the end. Both of these processes are extremely laborious and ripe for automation.
Enter NLP-based document classification (A.K.A. categorization). A properly-trained system can instantly determine which products or services (entities) are mentioned, along with associated topics and themes. Where relevant, sentiment analysis adds another layer of metadata for “ticket triage”. A strongly negative ticket, of course, should probably be dealt with first.
The clearest ROI from automated support ticket classification is in time savings. At larger contact centers, shaving 5 seconds off the end of each call quickly adds up to thousands of person-hours saved each month. Meanwhile, the more reliable your ticket categorizer is, the more you can trust that data as the basis of deeper analytics. A product manager, for example, would love to know about a 200% increase in the number of negatively-weighted tickets that mention his or her particular product line. The ROI here is more nebulous, yet potentially even more valuable.
Automated Invoicing by Combining OCR with NLP Capabilities
Text analytics plays well with other technologies, such as Optical Character Recognition (OCR). Working together, an OCR tool and a text analytics system can scan a document, extract the information from it, and then structure that data to feed into another system. Text analytics machine learning models can also identify and correct errors in the scanned data. For example, Lexalytics, an InMoment company, models can find and fix erroneous line breaks with accuracy scores of 90% or higher.
An invoice processing use case is the perfect place to see these synchronous automations in action. When you combine an OCR bot with a semi-structured data parser and an NLP model, you can quickly and reliably:
- Extract all of the people, companies, products and deliverables, currency amounts, dates, and other pertinent information involved.
- Analyze this data to understand the relationships between each element, such as what dollar amount is owed by company V to firm W for delivery of X number of Y products on Z date.
- Insert the data into the appropriate places across any number of databases.
- Trigger a payment from accounts payable, or simply ping the accounting manager to take over from there
Contract Analysis for Regulatory Compliance
A similar technology combination applies well to other structured and semi-structured document use cases. Applying text analytics to contract analysis, for example, plays neatly into larger business processes like regulatory compliance.
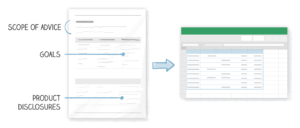
An Australian financial services firm uses text analytics to quickly review Statement of Advice (SoA) documents. These documents are often dozens of pages long. And even though SoAs share a similar structure, the data within them can vary wildly. Combining semi-structured data parsing with text analytics allows the firm to consistently (and quickly) review hundreds of SoAs at a time for disclosure compliance and suspicious recommendations.
Medical Document Processing Using Semi-Structured Data Parsing & NLP Models
Legal, financial, and medical documents are particularly onerous to process by hand. Diagnostic and procedure code updates, for example, add up to hundreds of pages every month. Processing just one of these by hand can take hours. Other files, like medical history records and discharge summaries, are filled with complex information that’s hard to parse at scale.
And of course, no two files are exactly alike: formats change, pieces are added and removed, and the data within each element is almost never totally consistent.
This is where text analytics automations streamline and accelerate the process. First, a semi-structured data parser identifies where data is located within the document. Then, an NLP model parses that data to understand the type and value of each datum, and the relationships between data points. The semi-structured parser will recognize, for example, that a certain alphanumeric string appears in a table near another entity underneath the header “Anesthesia”. Then the NLP will understand that the string represents a diagnostic code, the entity is the type of procedure, and that elsewhere in the document, those two values are syntactically associated with certain phrases that explain changes to billing rules.
Once the data is extracted and structured, the system distributes it into the appropriate locations across a number of databases. From there, other RPA bots can pick up that data and so something else with it.
Zooming Out: The Future of RPA is in Larger, Transformational Initiatives
Robotic Process Automation is an emerging market. Currently, more than 50% of companies with RPA initiatives have less than 10 bots in production. But Gartner reports that RPA is the fastest-growing software subsegment they track. The RPA market grew by more than 63% year-over-year in 2018.
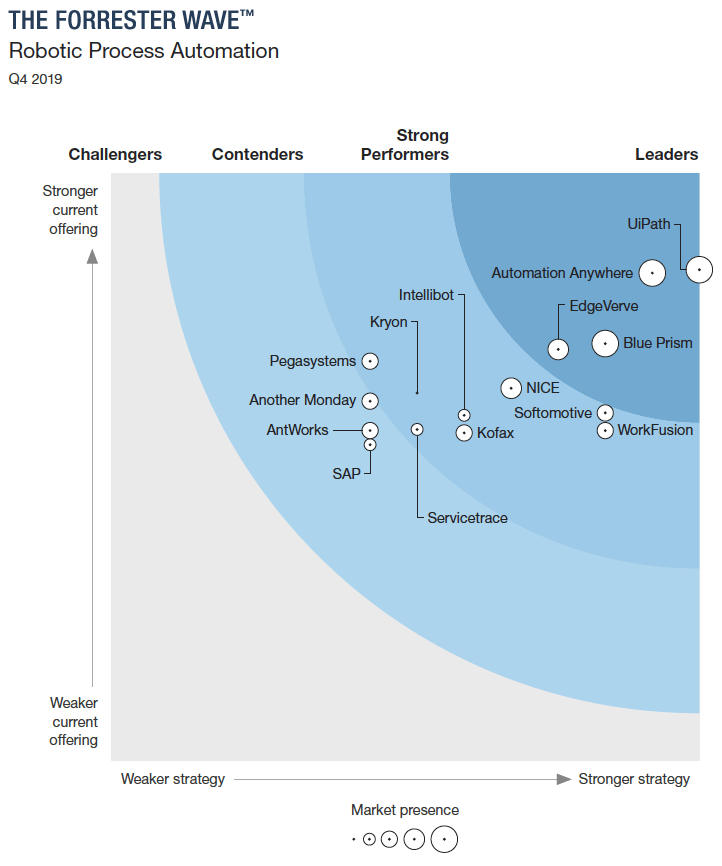
Forrester’s Q4 2019 Wave™ report on the state of the RPA market highlights 15 significant RPA vendors.
Gartner, meanwhile, includes 18 RPA vendors in their Q2 Magic Quadrant™.
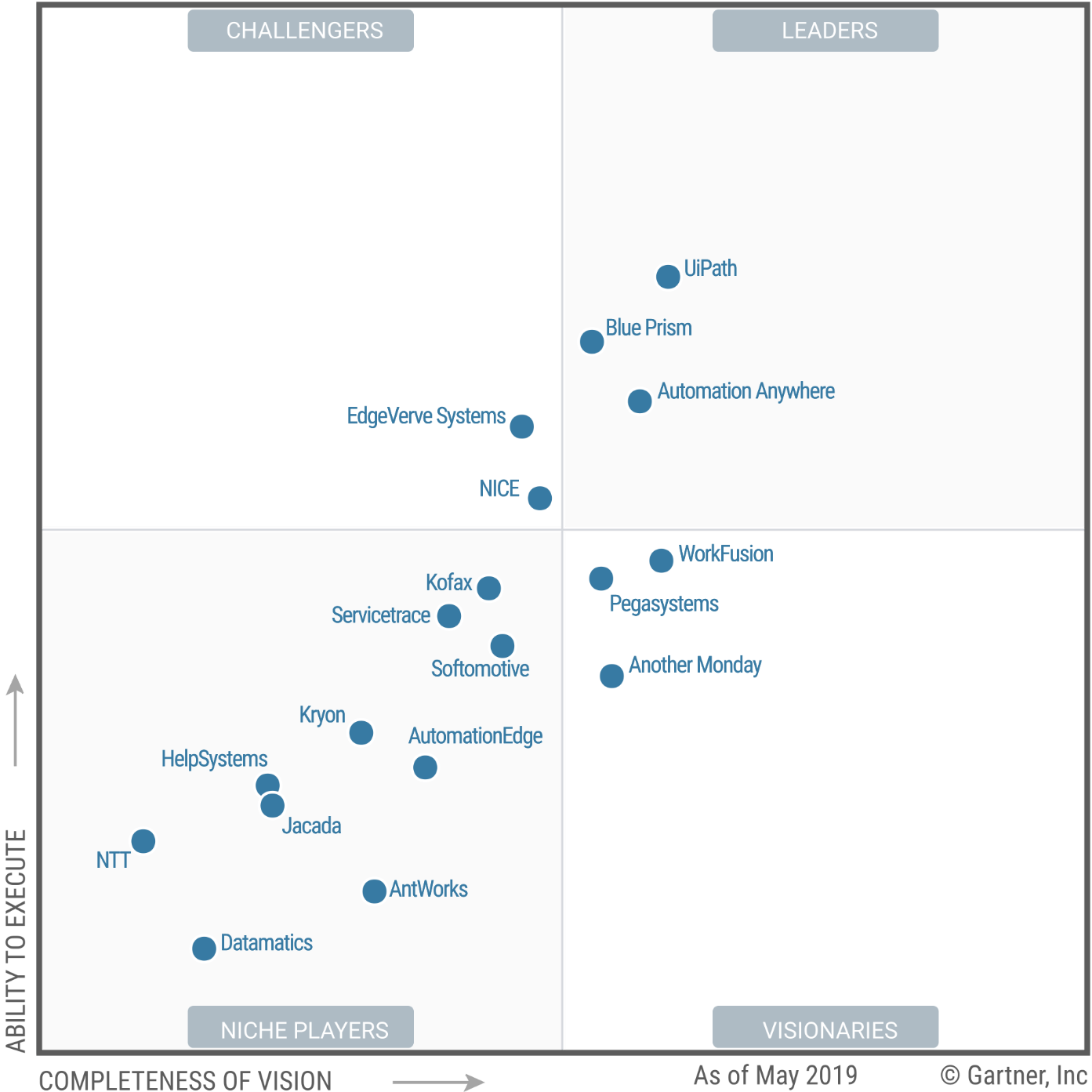
Notice how Forrester and Gartner highlight different companies. There is some overlap, of course. But the differences indicate that there is no agreed-upon standard for what people expect from an RPA vendor.
What’s more, both Forrester and Gartner emphasize a clear trend of enterprises moving beyond simple task automation towards larger, transformational RPA.
This is the difference between an RPA script that simply distributes data entered by a clerk across a database, and a collection of RPA bots that…
- Extract data from a scanned invoice
- Analyze it to understand the roles, amounts, dates, and other key points
- Distribute that data across a number of databases
- Automatically trigger a transaction from accounts payable
- Send a notification to the relevant people
…all without requiring any human input whatsoever.
Larger RPA Initiatives Will Require More Customization by the Vendor
No two enterprises operate in exactly the same manner with exactly the same data. There are similarities in data formats and procedures, of course. But more and more variations enter the system as you automate more and more tasks and processes. Therefore, as companies automate larger and larger processes, the similarities between RPA deployments will diminish.
Put another way: The larger the process being automated, the more customization will be required by the RPA vendor.
Finally, it’s important to note that Forrester explicitly discusses how firms increasingly want to combine RPA bots with other analytics components, including text analytics and metadata analysis, to address broader use cases.
However, Forrester’s and Gartner’s RPA vendor profiles reveal that many are lagging behind in supporting “trending text analytics use cases”. Others have stronger natural language processing but lack capabilities with unstructured document use cases involving PDFs and similar files. And many are having trouble fitting text analytics/NLP components into their larger environment.
Further Reading: Text Analytics & NLP in RPA
The above are just a few examples of text analytics use cases in robotic process automation. For more applications of text analytics and NLP in RPA, we recommend these resources:
- Six surprising ways businesses are impacted by RPA, OCR and NLP (Information Age)
- Top Applications of Text Analytics & NLP in Healthcare (Lexalytics)
- Artificial Intelligence and Robotic Process Automation (Expert Systems)
- RPA and AI – The New Intelligent Digital Workforce (Kofax)