Adding new natural language processing (NLP) capabilities to a product, application or other analytics infrastructure? Answer this question before anything else: Should I build my own system from open source components or license an NLP provider’s solution?
“Build or Buy” for text analytics and NLP means choosing between:
- Building from open source
- Licensing a basic cloud API
- Customizing an NLP platform
Open source NLP models are better than ever, and cloud NLP APIs are a simple search away. Today, you’re faced with dozens of free toolkits to choose from and scores of text analytics vendors vying for your attention.
This article will help you make an informed decision by explaining the choice you face, what to expect if you choose to build, and how to select an NLP provider if you decide to integrate an API or license a platform.
Summary & Key Take-Aways
If you take nothing else away from this article, let it be this: Building your own NLP system from open source can be a viable choice but is rarely the best one.
Instead, look to license and configure an API or NLP platform based on four factors: Document types, data volumes, analytical needs, and other requirements.
For simple use cases, such as document-level sentiment scoring or simple classification, go with a basic text analytics API or other NLP tool.
For detailed text analytics, such as multi-layered sentiment scoring, complex categorization, or recognition of custom entities, or if you’re handling complex documents, work with a configurable NLP platform.
Building from open source NLP libraries
- System cost: $0 (open source)
- Expertise cost: $81,000+ (hiring someone with NLP skills + other developers)
- Timeline: Weeks
- Capabilities: limited without major additional work
Licensing an API or NLP platform
- System cost: $10,000 (basic cloud analytics) to $40,000+ (configurable NLP platform)
- Expertise cost: None (your vendor will do most the work)
- Timeline: Days
- Capabilities: Both deep and broad, custom to your needs
What is a “Build or Buy” Question?

A build or buy question is a choice of whether to build your own version of something or buy a prefab (“off-the-shelf”) solution from another company. People face build or buy questions every week: Cook dinner or order delivery? Manage my own investments or pay an advisor? Do my own laundry or bring it to a cleaner?
Another way to think about this is the difference between building or fixing up a car versus buying a new one. Sure, it might be fun to build your own internal combustion engine from scratch. But you have errands to run, and the time you spend fixing your car is time you could be spending getting groceries, taking your kids to daycare, or meeting up with friends.
Building from Open Source NLP: Text Analytics Basics
Building your own NLP system from open source libraries can be a viable choice but is rarely the best one.
Why? Because even though building a very basic NLP tool is relatively simple, building something that’s actually useful is much, much harder.
Much like a car, any NLP system worth its salt involves a huge number of complex moving parts. When you buy an off-the-shelf solution, most of these are taken care of by the vendor. But when you build a text analytics system from scratch, you’re responsible for all of them.
There are 7 basic functions of text analytics, each of which serves a key role in deeper natural language processing.
This chart shows a simplified view of the layers of processing an unstructured text document goes through to be transformed into structured data at Lexalytics, an InMoment company.
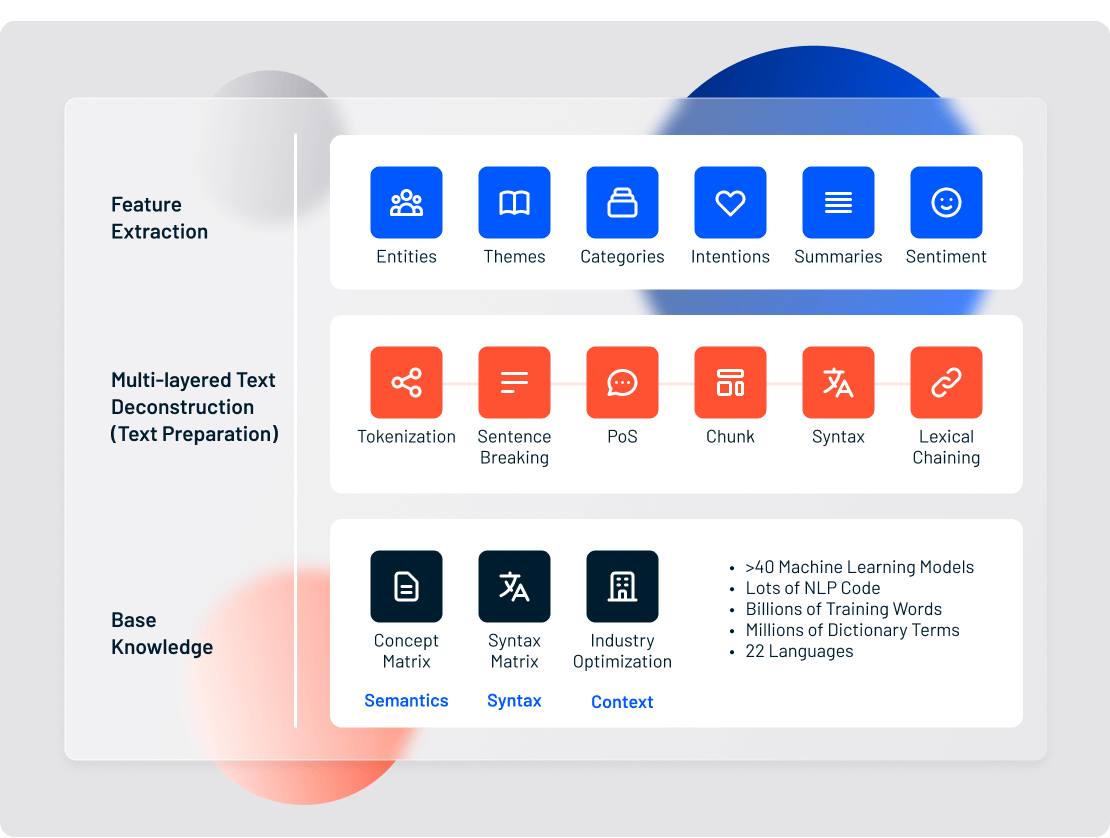
All that, and machine learning models are only in the footnote. Language detection, Part of Speech tagging, named entity recognition and other functions all require machine learning models to achieve reasonable accuracy. Each model must be trained on a data set consisting of hundreds or thousands of hand-tagged documents.
And that’s only the tip of the iceberg. If you’re thinking about building your own system, you need to understand the misleading simplicity and hidden dangers of basic NLP features.
The Limitations of Basic NLP: Sentiment Analysis & Categorization
![[man with 3 sentiment bubbles above his head.png]](https://www.lexalytics.com/wp-content/uploads/2022/04/sentiment1.png)
Rules-based sentiment analysis and query-driven categorization are pretty simple concepts. If you work from open source libraries while deliberately limiting the scope of your system, you can get a basic sentiment scorer or classifier up and running relatively quickly.
Similarly, three of the Big Tech companies (Google, Amazon, and Microsoft) offer cloud NLP services, including sentiment and topic analysis. If your analytical needs are simple, if you don’t need on-premise processing, and if you don’t have very many documents, these tools can be an efficient and cost-effective choice.
Don’t jump the gun, though. Open source NLP is good for simple use cases. But the cost-benefit analysis comes out against it unless you already have an established data science program. Similarly, the big cloud providers are good at solving lower-volume use cases involving one or two basic NLP features. But these tools offer narrow analytics and limited tuning. When you need more complex analyses or custom configurations, they simply won’t support you.
This is important because basic text analytics comes with a number of drawbacks. For example, document-level sentiment scores can be misleading because they’re taken out of context.
Imagine a restaurant review that reads, “The linguini was great, but the room was way too dark.”
Clearly this expresses positive sentiment towards the linguini, and negative sentiment towards the room’s ambience. But a document-level sentiment tool will return the average of these two scores, reporting it as neutral.
This example shows how rules-based document-level sentiment analysis can be dangerous, especially if you’re making important decisions based on the results. For more, read this paper: Theme Extraction and Context Analysis.
The point is, basic text analytics is useful, but only to a point. When you need deeper insights or custom analysis capabilities, you need advanced NLP.
The Costs of Building Advanced NLP with Machine Learning
Advanced NLP features such as entity- and topic-level sentiment, categorization of ambiguous words, and theme analysis are powerful data analysis tools. But building these features requires you to combine NLP rules with custom machine learning models. And this adds considerable cost to your project.
According to Glassdoor, the average salary for a United States-based natural language processing engineer is more than $80,000. Hiring a single data scientist to train NLP machine learning models will run you well into the six figures, plus benefits and bonuses.

On top of hiring NLP engineers and data scientists, you’ll need to gather, clean and annotate data to train models on. A single NLP categorization model, for example, demands at least 100 pieces of training content. Language-specific sentiment models or Part of Speech taggers require thousands more. Each data set must be gathered, carefully cleaned, and painstakingly annotated by hand before being fed to the model. If you don’t have a good pipeline for processing data and managing the complexity as your models grow over time, you’ll quickly run into problems.
To sum up: to build your own NLP system that’s actually capable of delivering deep, useful insights, you’re looking at upwards of $100,000 or more in talent and data costs. And that’s in addition to the thousands of people-hours they’ll have to spend building, tuning and re-training the system.
Choosing an NLP Solution: 4 Factors to Consider
To reiterate: Building your own NLP system from open source libraries can be a viable choice but is rarely the best one.
In most cases, it’s far more cost-effective to license an API or NLP platform. Which approach and what vendor is best for you? Start by understanding your own needs. Make your choice based on these four factors:
- Document types
- Data volumes
- Analytical needs
- Other requirements
 First, consider the type of documents you’re dealing with. Simple survey verbatims? Try an open source NLP model or the text analytics capabilities of your survey tool. Unstructured content like customer reviews, free-text surveys, and social media comments? You’ll need a dedicated NLP tool to handle them. Contracts, invoices, emails, medical files or other complex documents? Look for a fully customizable NLP solution supported by an established vendor.
First, consider the type of documents you’re dealing with. Simple survey verbatims? Try an open source NLP model or the text analytics capabilities of your survey tool. Unstructured content like customer reviews, free-text surveys, and social media comments? You’ll need a dedicated NLP tool to handle them. Contracts, invoices, emails, medical files or other complex documents? Look for a fully customizable NLP solution supported by an established vendor.
Next, evaluate the volume of data you process per month, on average. A few hundred or a couple of thousand documents can easily be handled by an open source model or cloud API. Beyond that, open source runs into performance issues and cloud solutions get very expensive. If you’re handling tens of thousands of documents or more, look for a scalable NLP tool with predictable pricing and stable, scalable architecture.
Thirdly, evaluate your analytical needs. Document-level sentiment analysis, simple categorization, or recognition of standard entities can usually be handled by open source models or even an application-specific solution such as a survey tool. When you want to understand why people feel the way they do, define custom entities or sort content into complex buckets, however, you’ll need an NLP platform with tuning and configuration tools.
Finally, list out your other requirements, such as private data storage, on-premise processing, semi-structured data parsing, a high level of support, or specific services like custom machine learning models.
Open source NLP models can process documents on-premise but leave you to fend for yourself with training. Cloud analytics providers may offer private storage, but you can’t know where your data actually goes when you call their API. Meanwhile, the Big Tech companies don’t offer much in the way of services and training – after all, they’re not in the NLP business, they’re in the cloud business.
Only dedicated NLP companies like Lexalytics combine all of the technology necessary to meet your requirements with the expertise and know-how needed to help you actually meet your goals.

Summary: Build or Buy For Natural Language Processing?
So, should you build or buy for text analytics and NLP?
Building from open source
Pros: free NLP libraries; complete control over the build; on-premise processing; build up internal capabilities
Cons: takes time to build; no support or services; requires expertise; limited analytics without major additional work
Licensing an API or NLP platform
Pros: start analyzing immediately; more analytics capabilities; tune and configure as you need; someone else maintains the core tech; full support and services
Cons: licensing costs; need to tune the engine; choosing the wrong provider leads to big headaches down the road
And perhaps most importantly: Choosing to buy, rather than build from scratch, frees you up to focus on actually achieving your goals: improving products and customer experiences, reducing employee turnover, managing regulatory compliance, automating business processes, or something else entirely.
Questions? Drop us a line to discuss your own choice.
