Theme Extraction and Context Analysis
Context analysis of text documents involves using natural language processing (NLP) to break down sentences into n-grams and noun phrases and then
evaluate the themes and facets within. In this white paper, we’ll explain the value of context in NLP and explore how we perform theme analysis on unstructured text documents.
The goal of natural language processing (NLP) is to find answers to four questions:
- Who is talking?
- What are they talking about?
- How do they feel?
- Why do they feel that way?
This last question is a question of context. Imagine a pundit’s tweet that reads:
“Governor Smith’s hard-line stance on
transportation cost him votes in the election.”
Entity-based sentiment analysis of this sentence will indicate that “Governor Smith” is associated with negative sentiment. But that’s all you have: the knowledge that the Governor is viewed negatively. Wouldn’t it be even more helpful to know why?
This is where theme extraction, which identifies the subjects and ideas that link many different text documents together and, more broadly, context analysis which helps data analysts understand why people feel the way they do, come into play. Performing theme extraction on this sentence might give us two results:
“hard-line stance”
“budget cuts”
Suddenly, the picture is much clearer: Governor Smith is being mentioned negatively in the context of a hard-line stance and budget cuts. Notice that this second theme, “budget cuts,” doesn’t actually appear in the sentence we analyzed. Some of the more powerful NLP context analysis tools out there can identify larger themes and ideas that link many different text documents together, even when none of those documents use those exact words.
Remember: it’s not uncommon to find data analysts processing tens of thousands of tweets like this every day to understand how people feel. But without context, this information is only so useful. Contextual analysis helps you tell a clear, nuanced story of why people feel the way they do.
The Foundations of Context Analysis
The foundation of natural language processing (NLP) context analysis is the noun. Of course, this is true of named entity extraction as well (see our entity extraction white paper for more details). But while entity extraction deals with proper nouns, context analysis is based around more general nouns.
For example, where “Cessna” and “airplane” will be classified as entities, “transportation” will be considered a theme (more on themes later).
Lexalytics supports four methods of context analysis, each with its merits and disadvantages:
- N-grams
- Nouns
- Themes
- Facets
Let’s start with the n-grams first and work our way through the other three methods in the list.
Using N-Grams For Basic Context Analysis
N-grams are combinations of one or more words that represent entities, phrases, concepts, and themes that appear in text. Generally speaking, the lower the value of “n,” the more general the phrase or entity.
N-grams form the basis of many text analytics functions, including other context analysis methods such as Theme Extraction. We’ll discuss themes later, but first it’s important to understand what an n-gram is and what it represents. There are three common levels of n-gram:
- 1 word: MONO-gram
- 2 words: BI-gram
- 3 words: TRI-gram
To get an idea of the relative strengths and weaknesses of mono-grams, bi-grams, and tri-grams, let’s analyze two phrases and a sentence:
“crazy good”
“stone cold crazy”
“President Obama did a great job with that awful oil spill.”
Here’s what we extract:
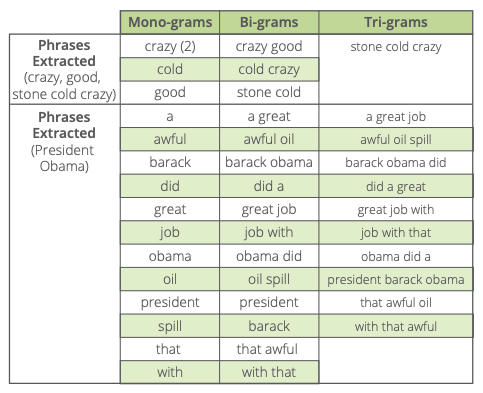
What Conclusions Can We Draw?
First, the mono-grams (single words) aren’t specific enough to offer any value. In fact, monograms are rarely used for phrase extraction and context. Instead, they offer other value as entities and themes.
Tri-grams aren’t much use either, for the opposite reason: they’re too specific. If you happen to be searching for very particular phrases in a document, specificity can be useful. But tri-grams usually offer too narrow a lens to look through. In the end, tri-grams are used for phrase extraction, but not as frequently as bi-grams.
That leaves us with bi-grams. If n-grams are bowls of porridge, then bi-grams are the “just right” option.
As demonstrated above, two words is the perfect number for capturing the key phrases and themes that provide context for entity sentiment.
But be warned: N-grams can come with a lot of “noise.” Phrases such as “with that,” which technically are bi-grams, offer no value in context determination, and do little more than clutter your view.
Using Stop Words to Clean Up N-Gram Analysis
Left alone, an n-gram extraction algorithm will grab any and every n-gram it finds. To avoid unwanted entities and phrases, our n-gram extraction includes a filter system.
Stop words are a list of terms you want to exclude from analysis. Classic stop words are “a,” “an,” “the,” “of,” and “for.”
In addition to these very common examples, every industry or vertical has a set of words that are statistically too common to be interesting.
Take the phrase “cold stone creamery,” relevant for analysts working in the food industry. Most stop lists would let each of these words through unless directed otherwise. But your results may look very different depending on how you configure your stop list.
If you stop “cold stone creamery,” the phrase “cold as a fish” will make it through and be decomposed into n-grams as appropriate.
If you stop “cold” AND “stone” AND “creamery,” the phrase “cold as a fish” will be chopped down to just “fish” (as most stop lists will include the
words “as” and “a” in them).
N-gram stop words generally stop entire phrases in which they appear. For example, the phrase “for example” would be stopped if the word “for” was in the stop list (which it generally would be).
Advantage of N-grams
- Offers thematic insight at different levels (mono, bi-, and tri-grams)
- Simple and easy to conceptually understand
Drawbacks to N-grams
- Indiscriminate: requires a long list of stop words to avoid useless results
- Simple count does not necessarily give an indication of “importance” to text or of its importance to an entity
Noun Phrase Extraction
The form of n-gram that takes center stage in NLP context analysis is the noun phrase. Noun phrases are part of speech patterns that include a noun. They can also include whatever other parts of speech make grammatical sense, and can include multiple nouns. Some common noun phrase patterns are:

So, “red dog” is an adjective-noun part of speech pattern. “Cavorting green elk” is a verb-adjective-noun pattern. Other part-of-speech patterns include verb phrases (“Run down to the store for some milk”) and adjective phrases (“brilliant emerald”).
Verb and adjective phrases serve well in analyzing sentiment. But nouns are the most useful in understanding the context of a conversation. If you want to know “what” is being discussed, nouns are your go-to. Verbs help with understanding what those nouns are doing to each other, but in most cases it is just as effective to only consider noun phrases.
Noun phrase extraction takes part of speech type into account when determining relevance. Many stop words are removed simply because they are a part of speech that is uninteresting for understanding context. Stop lists can also be used with noun phrases, but it’s not quite as critical to use them with noun phrases as it is with n-grams.
Advantages of Noun Phrase Extraction
- Restricts to phrases matching certain part of speech patterns
- Fewer stop words are needed and less effort is involved
Drawbacks to Noun Phrase Extraction
- No way to tell if one noun phrase is more contextually relevant than another noun phrase
- Limited to words that occur in the text of “importance” to text or of its importance to an entity
Themes and Theme Extraction
Noun phrases are one step in context analysis. But as we’ve just shown, the contextual relevance of each noun phrase itself isn’t immediately made clear just by extracting them. This is where themes come into play.
In a nutshell: Themes are the ideas and subjects that “connect” a set of text documents. Themes are themselves noun phrases, which we identify and extract based on part of speech patterns. Then we score the relevance of these potential themes through a process called lexical chaining. Lexical chaining is a low-level text analytics process that connects sentences via related nouns. (For more on lexical chaining, read our article on The 7 Basic Functions of Text Analytics.)
Once we’ve scored the lexical chains, themes that belong to the highest scoring chains are assigned the highest relevancy scores.
To demonstrate theme extraction, let’s use this older CNN article:
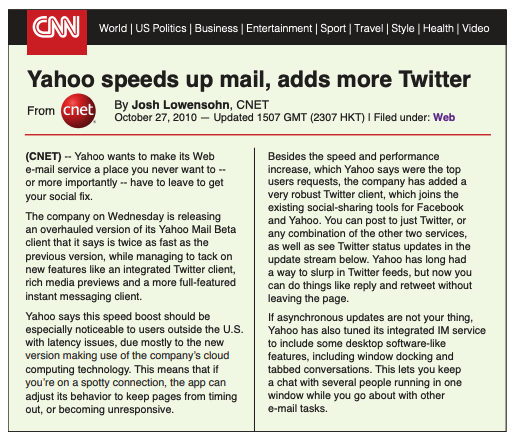
Processed by Lexalytics, this article’s top 5 themes are:
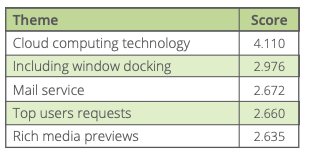
You can see that those themes do a good job of conveying the subjects and ideas discussed in the article. And scoring these themes based on their contextual relevance helps us see what’s really important. Theme scores are particularly handy in comparing many articles across time to identify trends and patterns.
In a production environment, Lexalytics goes one step further by including sentiment scores for every theme we extract. This is key in differentiating between the opinions expressed towards different entities within the same body of text.
Remember this sentence: “President Barack Obama did a great job with that awful oil spill.”
By sentiment-scoring individual themes, Lexalytics can differentiate between the positive perception of the President and the negative perception of the theme “oil spill.”
Advantages of Theme Extraction and Scoring
- Restricts to phrase matching certain part of speech patterns
- Fewer stop words needed, less effort involved
Drawbacks to Theme Extraction and Scoring
- No way to tell if one noun phrase is more contextually relevant than another noun phrase
- Limited to words that occur in the text of “importance” to text or of its importance to an entity
Facets: Context Analysis Without Noun Phrases
Sometimes your text doesn’t include a good noun phrase to work with, even when there’s valuable meaning and intent to be extracted from the
document. Facets are built to handle these tricky cases where even theme processing isn’t suited for the job.
Think about this sentence:
“The bed was hard”
There is no qualifying theme there, but the sentence contains important sentiment for a hospitality provider to know.
Now imagine a big collection of reviews. They may be full of critical information and context that can’t be extracted through themes alone. This is where facets come into play.
We should note that facet processing must be run against a static set of content, and the results are not applicable to any other set of content. In other words, facets only work when processing collections of documents. This means that facets are primarily useful for review and survey processing, such as in Voice of Customer and Voice of Employee analytics.
Noun phrase extraction relies on part-of-speech phrases in general, but facets are based around “Subject Verb Object” (SVO) parsing. In the above case, “bed” is the subject, “was” is the verb, and “hard” is the object. When processed, this returns “bed” as the facet and “hard” as the attribute.
The nature of SVO parsing requires a collection of content to function properly. Any single document will contain many SVO sentences, but collections are scanned for facets or attributes that occur at least twice.
Here’s an example of two specific facets, pulled from an analysis of a collection of 165 cruise liner reviews:
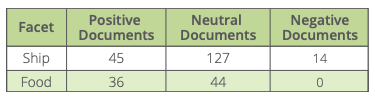
Each of these facets, in turn, are associated with a number of attributes that add more contextual understanding:
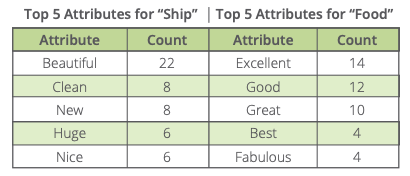
Judging by these reviews, this is a new ship with great food — the kitchen seems to be doing an excellent job.
Our facet processing also includes the ability to combine facets based on semantic similarity via our Wikipedia™-based Concept Matrix. We combine attributes based on word stem, and facets based on semantic distance.
Here’s an example:
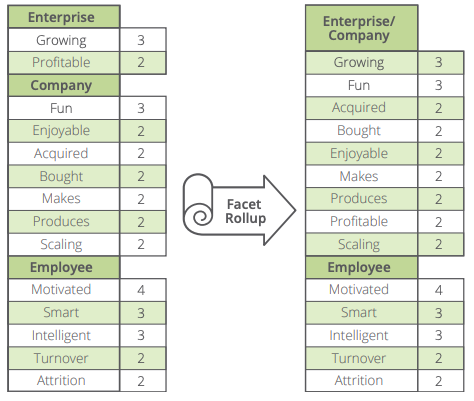
Enterprise and Company are combined into a single facet, providing you with even richer information by combining the attributes from both.
The Benefits of Natural Language Processing
Business intelligence tools use natural language processing to show you who’s talking, what they’re talking about, and how they feel. But without
understanding why people feel the way they do, it’s hard to know what actions you should take.
Context analysis in natural language processing involves breaking down sentences into n-grams and noun phrases to extract the themes and facets within a collection
of unstructured text documents.
Through this context, data analysts and others can make better-informed decisions and recommendations, whatever their goals.
Learn more about natural language processing and our expertise and what we’re doing at Lexalytics, an InMoment Company on our Resources page